Image Recognition Neural Network

Overview
This program is a deep learning neural network developed entirely without using any machine learning libraries, such as PyTorch or Tensorflow, using only pure Python and NumPy. Designed with guidance from the book Neural Networks from Scratch, this was made for educational purposes to learn of the mathematics and mechanics behind deep learning models.
Technical Details
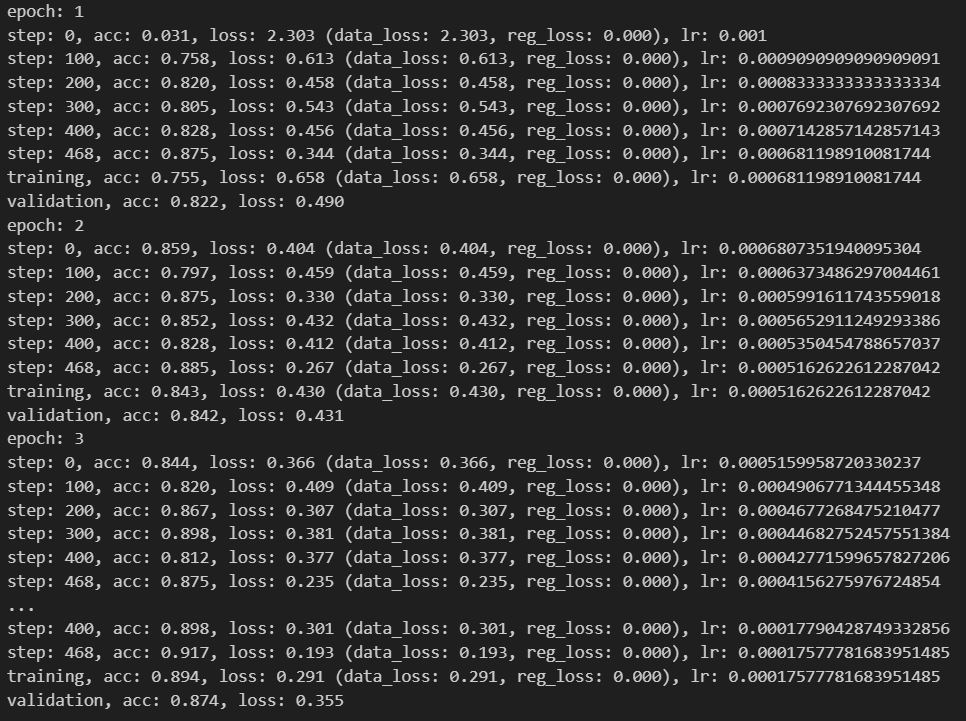
This AI model’s source code is written in Python utilizing the NumPy library, all on one Jupyter Notebook. The Jupyter Notebook allows each block of code to be organized and run separately from one another for ease of development and testing.
This model was trained on the Fashion MNIST dataset (accessable on Kaggle, examples of training data shown on top), a dataset containing tens of thousands of labeled 28x28 pixel images of articles of clothing.
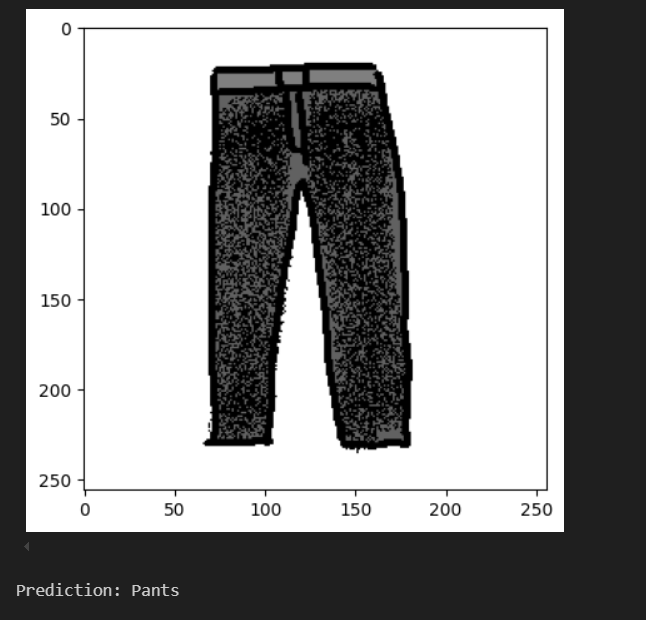
It is also indeed capable of recognizing pieces of clothing from test images, including hand drawn ones.
This model uses 3 layers: an input layer of 128 neurons, a deep layer of 128 neurons, and an output layer of 10 neurons. During the forward pass, each neuron takes in an input value, multiplies said value to a weight, and adds a bias value, creating the resulting output. Note that the “neurons” themselves are not actually “real”, as in there is no “neuron” class or object, it is just a way to represent the data being processed. In reality each layer takes in an input matrix, multiplies it to a weight value matrix, and adds a bias matrix.
This output is then sent through an activation function, in this instance the Reticulated Linear Activation (ReLU) function. The ReLU function essentially multiplies the output by 1 (keeps the output) if the output of the neuron > 0, and equates it to 0 otherwise.
During training, the final output then has its loss and accuracy calculated via categorical crossentropy.
Using the calculated loss, the model then initiates the backward pass, utilizing the Adaptive Moment Estimation (Adam) Optimizer function to update the various weights and biases used in the neural layers in order to reduce loss and increase accuracy through gradient descent.
This forward pass - backward pass process continues until the entirety of the training data has been processed by the model. The data itself is randomized during training to prevent the model from just memorizing a single kind of data (ex: memorizing what a shoe looks like and nothing else), and is also divided into smaller sets to allow for more efficient training.
This model utilizes a lot of math: most notably linear algebra, calculus, and partial differential equations.
Links
Github: Link